1
2
4
新手上路
本文首发至微信公众号:CVHub,不得以任何形式转载或售卖,仅供学习,违者必究!
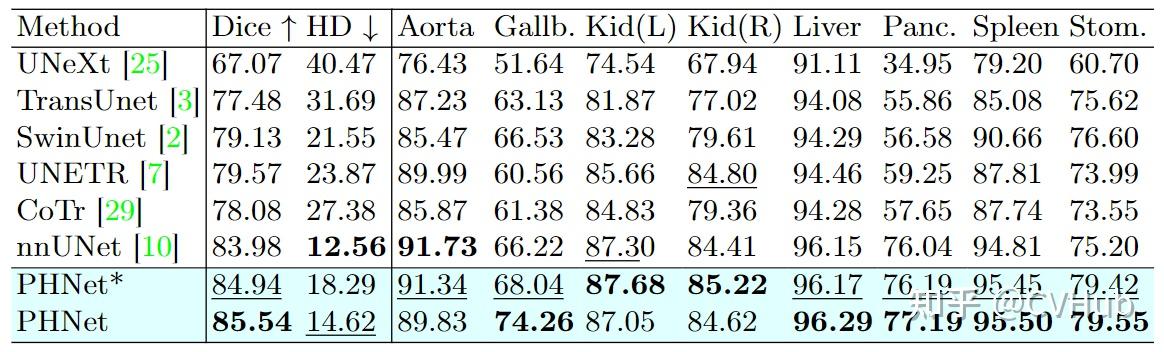
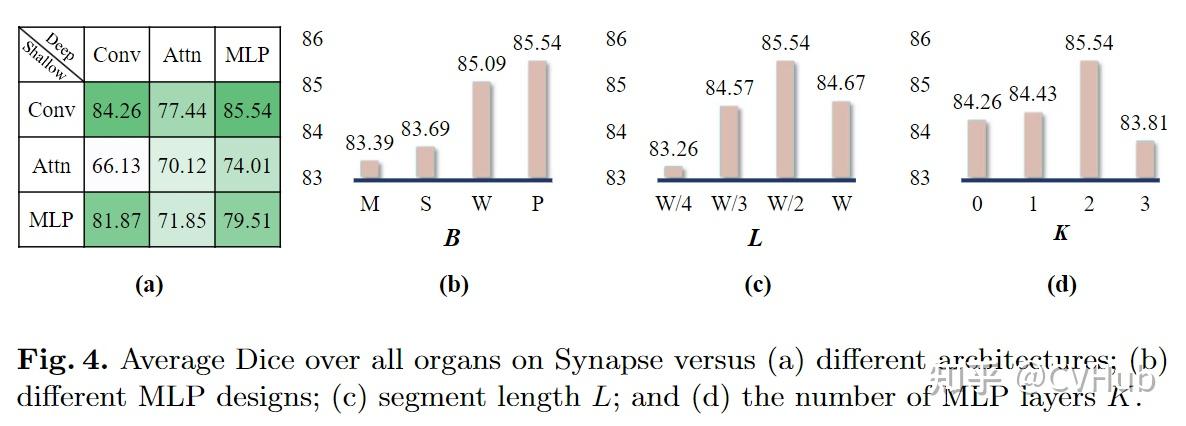
Title: A Permutable Hybrid Network for Volumetric Medical Image Segmentation PDF: https://arxiv.org/pdf/2303.13111 Code: coming soon...
使用道具 举报
3
7
12
0
本版积分规则 发表回复 回帖后跳转到最后一页



 发表于 2023-4-21 10:40:07
发表于 2023-4-21 10:40:07