这里涉及到的隐私分为三块。 ① 数据隐私
数据不管是对机构还是个人而言都是宝贵的财富,越是优质的数据越会存在独有的隐私保护要求。 ② 模型隐私
因为模型本来就是从数据中提取出来的一种模式,模型在训练的过程中需要去使用数据来训练,在模型训练交互的过程中模型如果没有保护好就可能通过模型反推出部分的输入数据,所以说这就是为什么我们也要把模型保护好。 ③ 参数隐私
因为参数是能够让模型发挥最大优势的一个约束,一个模型只有配备了合适的参数才能发挥最大的价值。
-- 02 预备知识
1. 隐私计算的技术分类
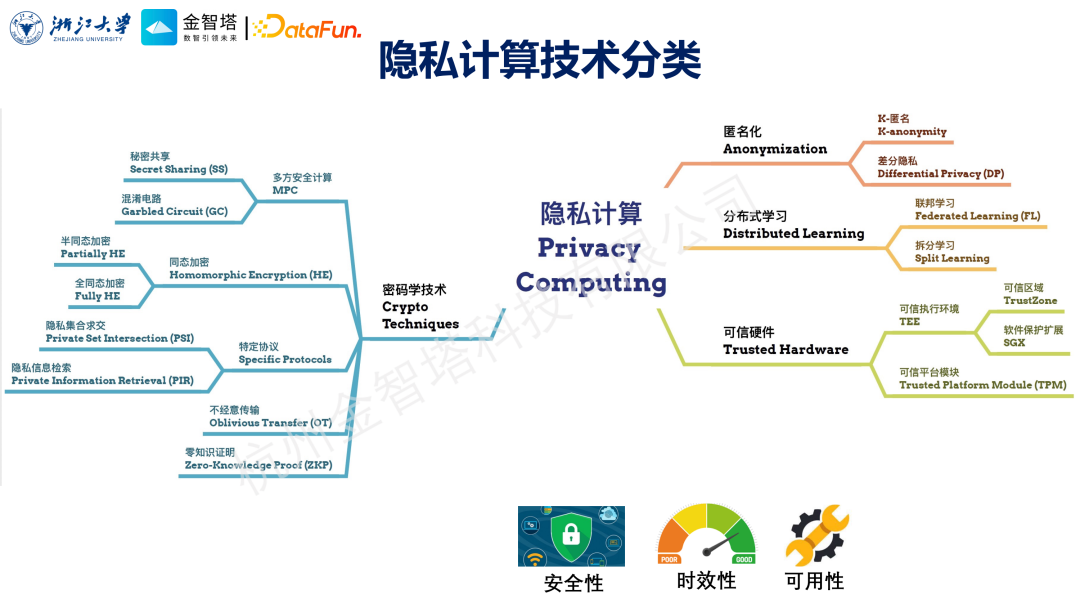
对于隐私计算技术的分类见仁见智,不同的人、不同的学术背景可能有不同的分类方法,这里我把它分为四类。
① 密码学
包括经典的MPC多方安全计算、同态加密,针对特定协议的一些算法比如隐私求交、隐秘查询等,还有一些通用的协议,比如不经意传输以及零知识证明,都属于密码学这个流派。 ② 匿名化技术
主要包括经典的K匿名和差分隐私技术。 ③ 分布式学习
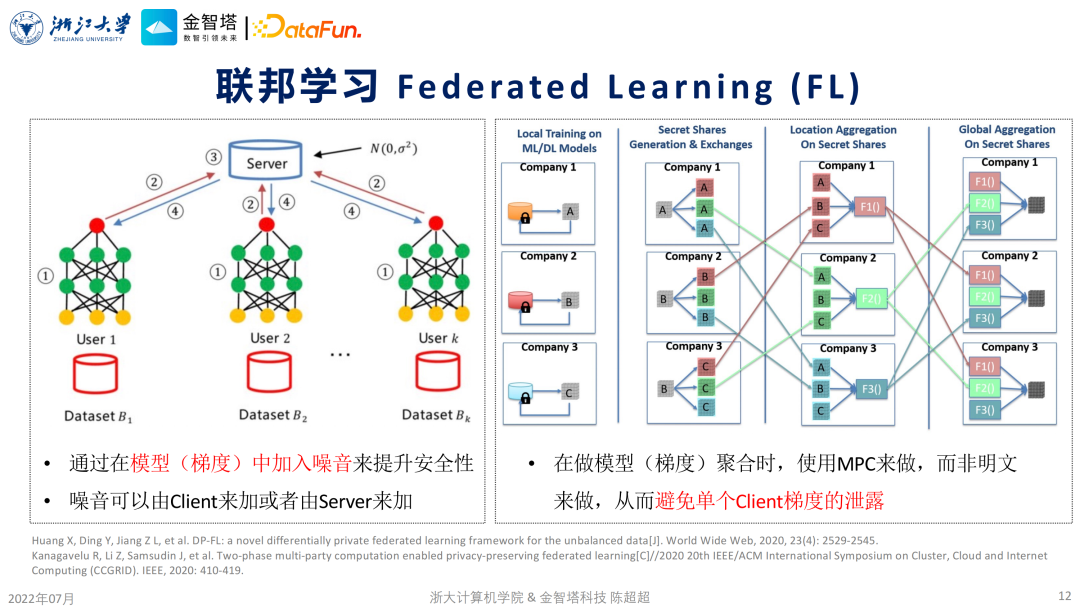
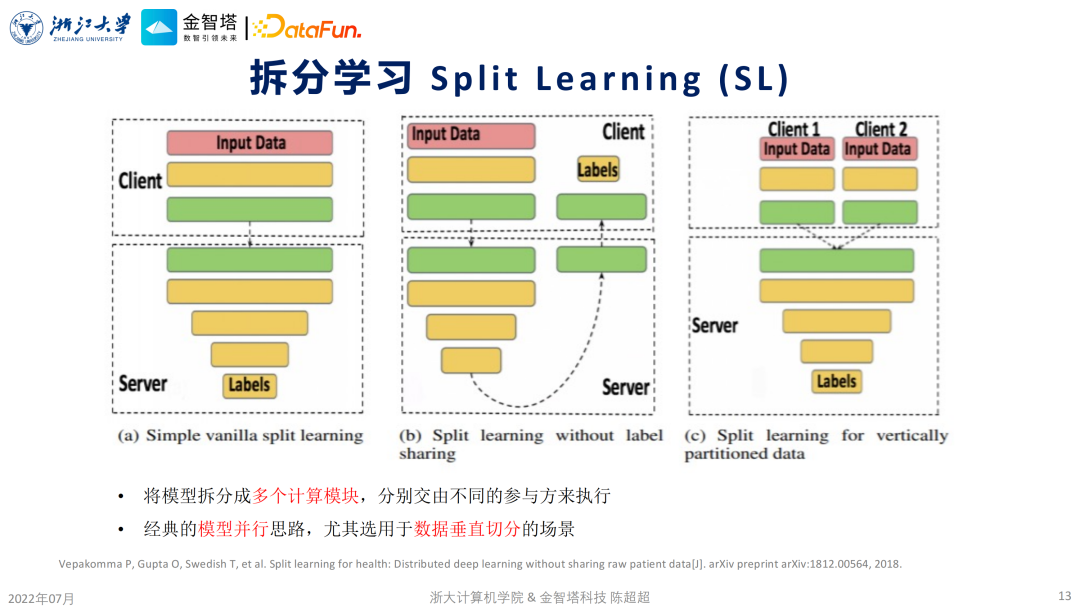
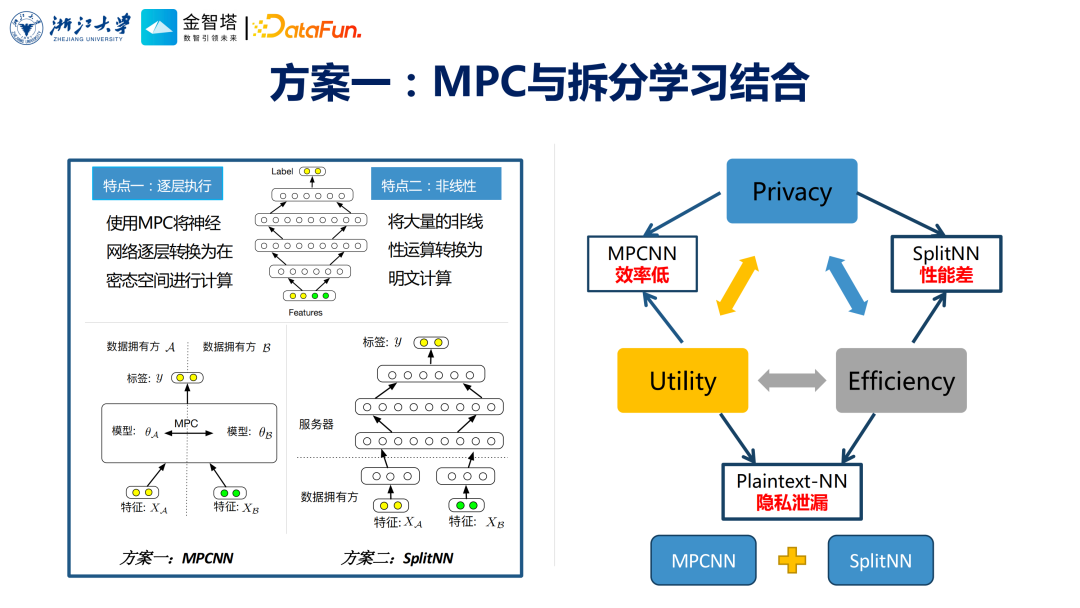
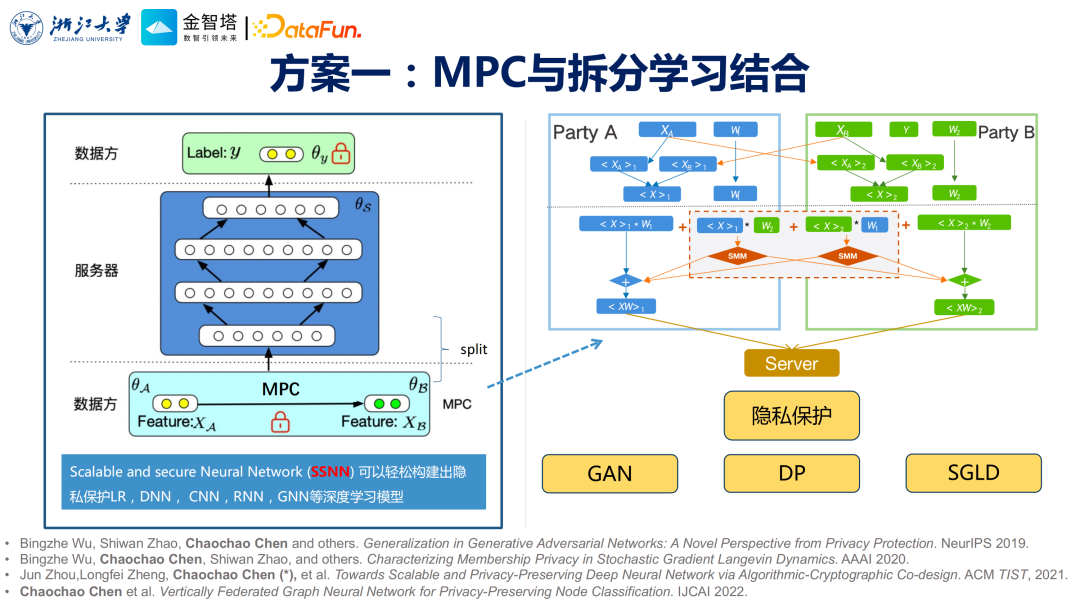
这里指的是有隐私保护属性的分布式学习,包含了两种,第一种就是大家非常熟悉的联邦学习,第二种就是拆分学习。 ④ 可信硬件
一类是TEE,一类是TPM。
每种技术路线各有优劣,主要表现是他们在安全性、时效性、可用性三方面不太一样。在实际业务场景中,需要融合不同技术路线,以提高安全、效率、易用三方面的平衡点。
2. 介绍隐私计算的几种技术
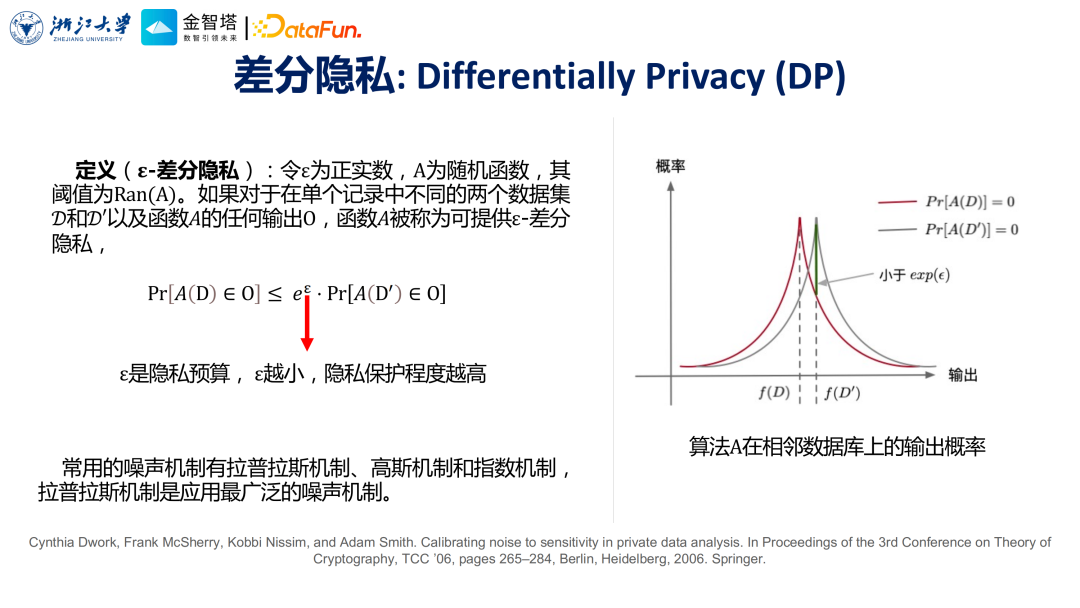
① 差分隐私
差分隐私是2006年Dwork等人提出的一种保护隐私的技术。它的定义是,给定两个相邻数据集(即两个数据集只相差一条记录),如果一个随机函数作用到这两个相临的数据集上之后,所得到的输出是不可区分的、是非常相近的,同时这个相近的程度可以用下图中的公式,用参数ε来表示,那么这个随机函数就满足ε差分隐私的性质,这个是差分隐私的定义。
同时这个ε越小,说明隐私保护的程度越高,需要加入的噪音的量也就越大。目前常用的加噪音的机制包括拉普拉斯机制、高斯机制、指数机制等。前两种机制通常用于给数值型的数据加噪音,比如一个人的收入之类的。指数机制通常会用于非数值型的,比如地址的噪音机制。
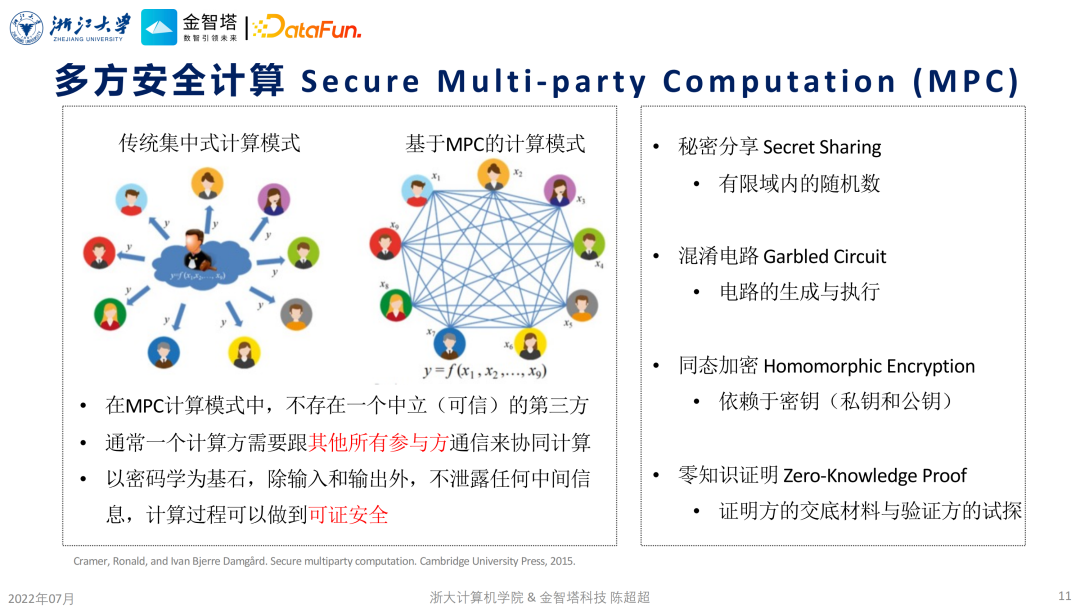
实际上,差分隐私具有非常优美的数学原理也是它非常受人青睐的原因之一。另外一个原因就其可操作性非常强,使用起来非常简单,只是在数据或者要保护的对象,比如模型或者模型的梯度上面加入一定的噪音,这样就能达到一定的保护效果了。 ② 多方安全计算



 发表于 2022-9-23 21:09:39
发表于 2022-9-23 21:09:39