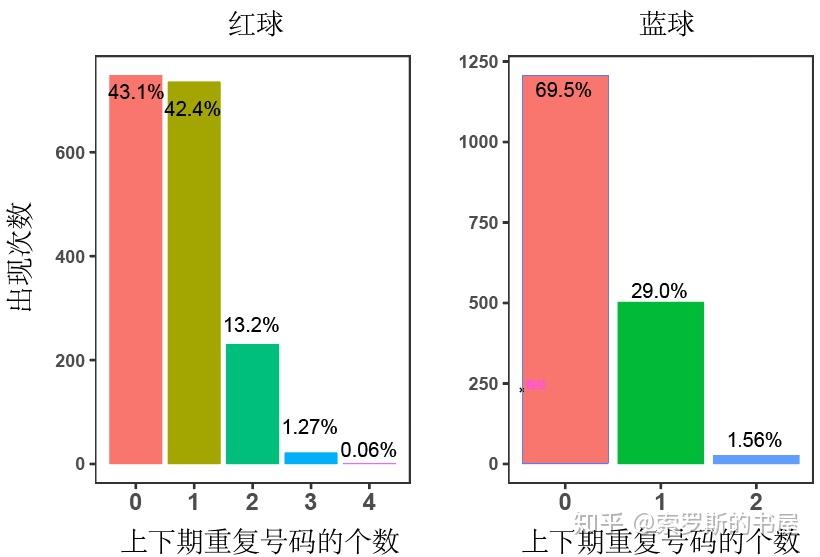
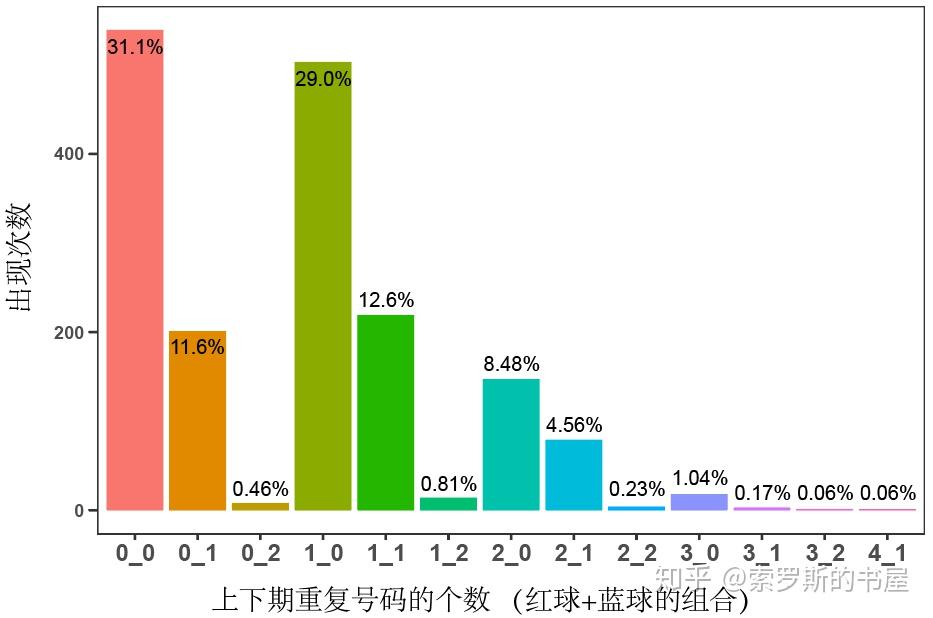
图中,"1_2"就表示红球中相邻2期有1个重复数字,蓝球中相邻2期有2个重复数字的情况,其他组合以此类推。可见,最容易出现的组合情况是"0_0"和"1_0"。接下来,小编想看看,在随机情况下,也就是瞎蒙的时候,上下期重复数字的个数跟我们观察到的实际结果是不是一致呢?简化模型如下:
以红球为例,从1-35这35个数字中随机抽取5个数字,抽取1万次,并标注先后序号。然后分析,在随机状态下,相邻2次抽取中,重复数字出现的次数。代码如下:
# model
D <- data.frame()
for (i in 1:10000) { ## 随机抽样1万次
D <- rbind(D, sample(1:35, 5))
}
E <- c()
for (j in 1:(1e5-1)) { ## 统计临近抽样的重复数字
E <- c(E, sum(c(t(D[j,]))%in%c(t(D[(j+1),]))))
}
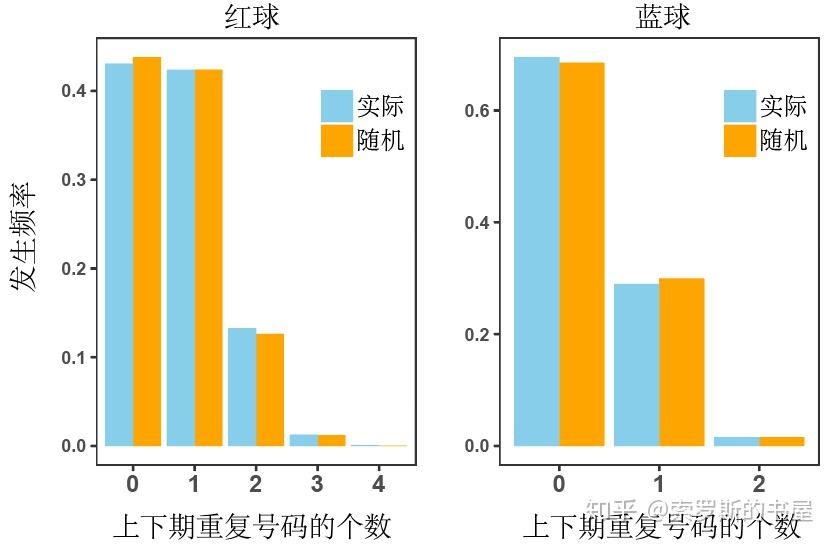
print (table(E))之后,把观察到的实际结果与随机的抽样结果放在一起比较,如下图:蓝色的柱子代表实际观察的比例,橙色的柱子代表随机抽样1万次得到的比例。



 发表于 2022-9-22 07:30:06
发表于 2022-9-22 07:30:06