|
|
先声明一下,本文内容没有任何的推广、诱导,只是作者本人的研究记录。
自从出了“系统帮选”的思路后,一个多月的时间,很多尼丝儿都获取了不错的推荐,拿到了很好的数据,迄今为止已经开出了2个一等奖和不少于10个二等奖。能看到这么好的数据,我这个“程序猿”也真的是很开心。近期也产生了一些新的想法,今天分享出来和大家一起探讨下。
当前使用最多的三种算法分别是参数冷热号算法(简称Hc)、三合一的Map算法以及自己寻找规律算法(简称Srf)。之前“系统帮选”的思路就是从最近10-20期里寻找各个算法的最优参数约30组,将其每一个作为一个“专家”,生成一组“专家数据”,再通过这些数据结合“专家逆推”工具来生成符合尼丝儿预算的结果。这种思路可形容为生成了一个选号池,这个池子比直接去随机摇号的池子要小很多,然后从这个池子里随机挑选数据给到大家,命中的概率会大大提升,也得到了验证。
新的思路我愿意称之为“系统追号”,不过我先提前说明下并不是追某一组具体的号码,而是追一组参数,再通过参数来生成号码。整体的原理是:
- 基础数据:每个算法的每组参数都会生成一组数据(针对Hc和Map算法结果是对1-33号排序后的结果,针对Srf结果是符合要求的几个数字),从这组数据里我可以选出固定位置那几个数字,固定位置的参数也可以通过程序来设定,再筛选出符合设定要求的参数;
- 优质数据:设定要求比如:最多预测红球数不超过9个,但最少命中不少于5个红球。对基础数据进行单一筛选、两两组合筛选、每三个一组筛选,选出符合设定要求的参数;
- 最终获取:对优质数据里的结果按参数进行分组,按命中的期数进行排序。暂定获取排名前20的参数,再从这些优质参数里去寻找覆盖面最广的。
我的最终目的就是能得到n组参数,每期能够生成n组数据,红球数尽量9个以内,这n组数据里有大概率至少有一组能够至少命中5+个红球,后续根据数据结果去尽可能的缩小n和每组预测数据里的红球个数。开干。
第一步:参数设定
最少命中的红球个数设定为5,最多的预测红球个数设定为9,也就是说我最后筛选出来的参数最次也是在某一期拿到过“9中5”的成绩的,当然最好的可能是每期都被这组参数命中了“5中5”。choose_position是针对hc和map算法时选取位置的index,0表示第一个,-1表示最后一个,这里主要还是针对头尾来取数(最热最冷的意思),总共选了14组位置参数,之前根据已有数据高命中率的一些位置参数还暂时没往里放。
autofollow_settings = {
'min_hitted_red_count': 5, # 最少命中的红球个数
'max_predict_red_count': 9, # 最多的预测红球个数, 9+1则意味着要168
'choose_position' : [ # 选取哪些位置的数据 - 针对hot_cold和map算法(从多到少、从热到冷排序后选择哪些index,这样设计主要是为了选择一些特定位置) - srf不需要
(0,1,2),
(0,1,2,3),
(0,1,2,3,4),
(0,1,2,3,4,5),
(0,1,2,3,4,5,6),
(0,1,2,3,4,5,6,7),
(0,1,2,3,4,5,6,7,8),
(-1,-2,-3,-4,-5,-6,-7,-8,-9),
(-1,-2,-3,-4,-5,-6,-7,-8),
(-1,-2,-3,-4,-5,-6,-7),
(-1,-2,-3,-4,-5,-6),
(-1,-2,-3,-4,-5),
(-1,-2,-3,-4),
(-1,-2,-3)
]
}第二步:训练基础数据
这步很简单,都还是按照基础的参数生成和组合规则,先生成参数,再通过参数来生成数据。然后根据第一步里设置的规则和choose_position,对每组参数生成的结果进行筛选。这里我用了个简单的方法:咱们的最终最低要求是9中5,那么也就是说最多能有4个数没命中,所以在筛选基础数据时,我设定的要求就是,每组基础数据最少命中一个,最多没命中的个数不超过4个。
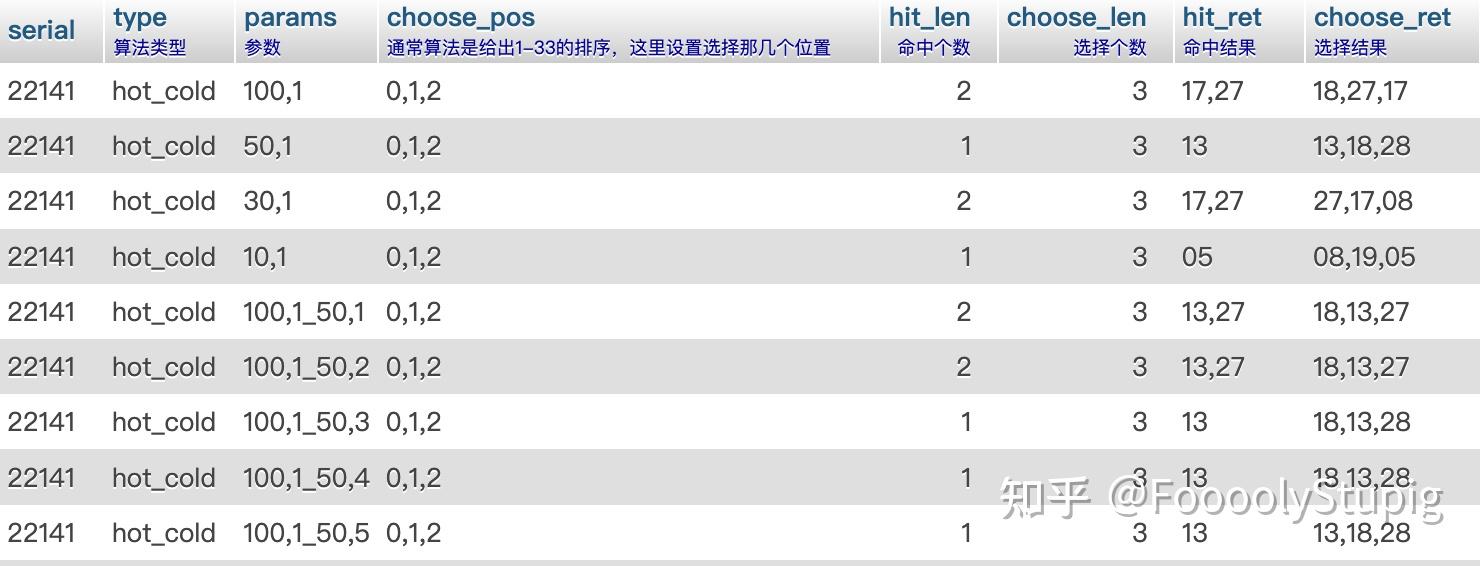

这一步还是跑了挺长时间,最终近100期的数据共计生成了1,719,299条基础数据,平均下来每期有1.7w条,数据库里占了160m多,突然有点不详的预感..
第三步:训练优质数据
操作方法不难,之前计划的是走三轮,第一轮是对基础数据做个简单的筛选,选出符合命中5个以上的;第二轮是对每期的基础数据进行两两组合,对选出的数据去重后,筛选出符合要求的参数;第三轮是每期内任选三个参数进行组合。但是后来计算了一下,平均每期17000组参数,两两组合的话会有接近1.5亿种组合,初步的拿一期数据评估了一下,按照当前的算力来跑得半个多小时左右。于是这一阶段果断选择放弃了任选三个参数的组合,咱可以简单算算,17000组里任选3组,大概有8188亿+种组合,我这小电脑加服务器跑上十天半个月都跑不完一期..
最终的方式每期的数据只跑两轮,开跑!
"Running..."
24个小时后,真相再一次无形的敲打了我,直接把服务器跑崩了...... 原来之前算的是平均每组里有17000组数,但实际上分布很不均匀,有的期里会有接近30000组数,这样算下来运算的时间整体是增加的,比想象中慢的多...而且数据量巨大。这一天的时间一共只跑了40期的数据,得到了5400多万条参数数据,共计占据了7.5GB的空间,吓了我一大跳啊。

简单统计了下可以看出:hc自己和自己组合的效果挺好的,其次就是hc和map的组合,不过能得到这么多的数据也是好事情!
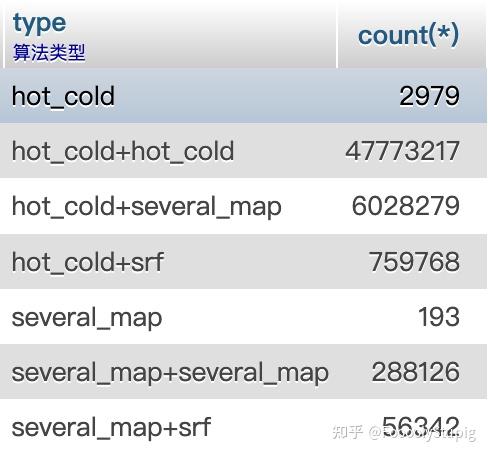
第四步:最终获取
因为服务器跑崩了,为了不影响线上的功能就先暂停了,看了下基于这40期数据的结果,结果还是很喜人的,按排序来看前20的参数,最好的一组参数直接覆盖了40期里的5期!筛了下这20组参数对应的期号,去重后覆盖量达到了27期,67.5%的覆盖率,心里确实已经是很满足了,不过这数据还没跑完,还不敢最终用起来..还得想想办法..
结语:
现在有些选择困难了,如果继续保持目前的参数配置,随时会崩溃,时间上扛不住,数据库也会扛不住。减少参数数量的话数据量会变少,但是覆盖面和中奖概率就都会下降了,也听听大家的想法呢,欢迎留言或私信啊,有任何好的想法都可以随时交流。 |
|



 发表于 2023-1-8 09:28:31
发表于 2023-1-8 09:28:31