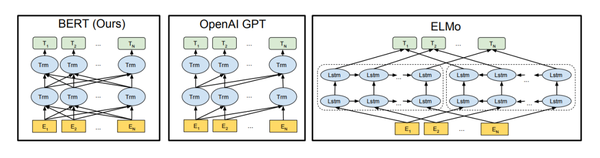
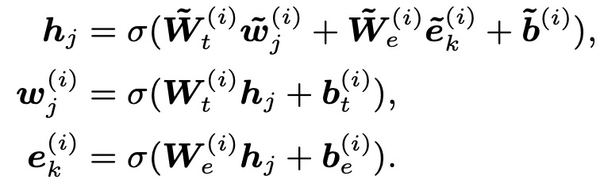预训练语言模型要从词向量说起。词向量利用文本数据,构造出词之间的共现关系,一般将在一句话中共现的词作为正样本,随机负采样构造负样本,采用CBOW或Skip-Gram的方式进行训练,以此达到让经常共现的词,能够具有相似向量化表示。其本质是NLP中的一个先验:频繁在文本中共现的两个词,往往语义是相近的。然而,词向量的问题也比较明显,同一个词在不同的语境中,含义往往是不同的,而词向量对于某一个词只能生成一个固定的向量,无法结合语境上下文信息进行调整。 Deep contextualized word representations(ACL 2018)提出了ELMo模型,利用双向LSTM模型结合上下文语境信息生成词的embedding。ELMo和以往的词向量模型最大的差别是,每个词的embedding都是整个句子的一个函数,即每个词的embedding和这个句子的上下文信息是相关的。ELMo语言模型的模型结构采用了一个正向LSTM和一个反向LSTM联合训练的方式,优化两个方向的语言模型优化目标。在完成训练后,每个单词在每层LSTM都会产生正向、反向两个embedding,对每个单词所有层的embedding拼接在一起,得到这个词在这句话中的embedding。ELMO在使用到下游任务时,会把数据每句话先过一遍ELMo,得到每个词的embedding,然后将ELMo生成的embedding和通过词向量得到的embedding拼接到一起,用于后续任务预测。
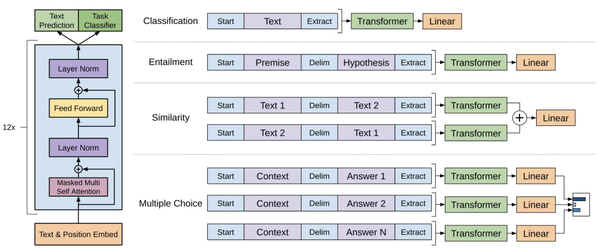
此后,语言模型预训练成为NLP中的核心之一。在Improving Language Understanding by Generative Pre-Training(2018)中提出了GPT模型。相比ELMo,GPT真正意义实现了pretrain-finetune的框架,不再需要将模型中的embedding取出来,而是直接把预训练好的模型在下游任务上finetune,对于不同任务采用不同的输入或输出层改造,让下游任务更贴近上游预训练模型。值得一提的是,在后续的prompt等优化中,又将下游任务向上游任务的贴近更近了一步,即将下游任务的输入和输出逻辑也进行变化去适应上游任务。让下游任务向上游任务对齐,是一个NLP中的发展方向。GPT模型主体采用的是Attention Is All You Need(NIPS 2017)提出的Transformer模型,使用的优化目标是正向语言模型。
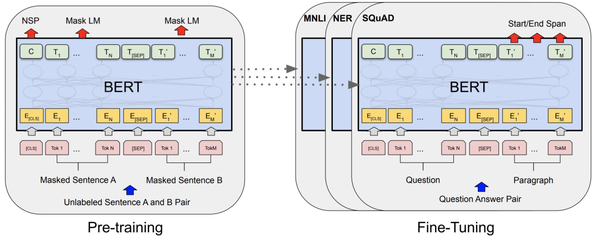
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(2018)提出了Bert模型,也是目前在NLP中应用最广泛的预训练模型之一。相比GPT和ELMo,Bert采用了一种Mask Language Model(MLM)这一不同的目标,通过随机mask掉输入文本中的某些token,然后利用上下文信息进行预测,实现对数据语义关系的提取。这种MLM相比之前的语言模型优化目标优点是,可以从多个方向同时进行信息抽取来预测当前token,而传统的语言模型(前向后后向)每一次只能从一个方向提取信息。即使将前向和后向结合,也无法实现真正意义上的同时利用前后文信息预测当前token。同时,Bert还引入了Next Sentence Prediction(NSP)任务,在预训练阶段构造了两个文本pair对输入,预测这两个文本的相关性。这个任务相当于是在sentence维度的信息提取,和下游的文本匹配类任务更加契合,这在单纯的语言模型中是难以学到的。
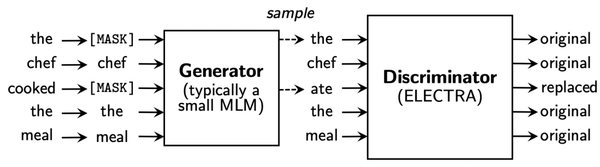
在Bert的基础上,有很多针对其的改进,这里我们主要介绍3个模型。RoBERTa: A Robustly Optimized BERT Pretraining Approach(2019)细致的对Bert模型的训练方式进行了对比实验和分析,并基于此总结出了能够提升Bert效果的训练方法。相比Bert,RoBerta的主要改进在于3个方面。首先采用了dynamic mask,即每个文本进入训练时动态mask掉部分token,相比原来的Bert,可以达到同一个文本在不同epoch被mask掉的token不同,相当于做了一个数据增强。其次,分析了训练样本应该如何构造,原来的Bert采用segment pair的形式,训练样本为两个segment组合到一起并使用NSP任务预测两个任务是否相关。RoBERTa发现从同一个document构造输入单句子的输入文本而非pair对,并且不使用NSP任务,效果会有一定提升。最后,RoBERTa增大了batch size以及对BPE(输入文本的分词方法进行了升级。 ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS(2020)提出了一个轻量级的Bert模型,以此降低Bert的运行开销。为了减少Bert资源开销,本文主要提出了两个优化:Factorized embedding parameterization以及Cross-layer parameter sharing。Factorized embedding parameterization对输入的embedding进行分解,原始的Bert将token输入的embedding维度E和模型隐藏层维度H绑定了,即E=H,前者表示每个token固有信息,后者表示每个token结合了上下文的动态信息,后者被证明是更重要的。因此本文提出可以让E和H解绑,选择一个较小的E不会影响模型效果,同时显著降低了由于输入词表V变大带来的内存开销上升。具体的,将E变成远小于H的维度,再用一层全连接将输入embedding映射到H维。这样模型embedding部分参数量从V*H下降到了V*E+E*H。Cross-layer parameter sharing让Bert每层的参数是共享的,以此来减小模型参数量。除了上述两个降低Bert运行开销的优化外,ALBERT提出了inter-senetnce loss这一新的优化目标。原来Bert中的NSP任务可以理解为topic prediction和coherence prediction两个任务。其中topic prediction是一种特别简单的任务,由于其任务的简单性,导致coherence prediction学习程度不足。本文提出将coherence prediction单独分离出来,相比Bert,正样本仍然是一个document相邻的两个segment,负样本变成这两个segment的顺序交换。 ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS(ICLR 2020)对pretrain阶段的MLM任务进行了优化。该方法的核心思路采用了GAN的思路。模型包括一个generator 和一个discriminator。输入文本仍然会被随机mask,然后generator会生成被mask掉的token,这里和MLM类似。而discriminator会判断每个位置的token是否是generator生成的(如果generator正好生成了正确的token,也认为其生成的是正确的)。通过这种对抗学习的方式,让discriminator预测被mask掉的token能力逐渐增强,也即从文本中提取信息的能力增强。最终的预训练模型使用的是discriminator部分。ELECTRA的缺点在于由于有了一个单独的Generator,模型整体开销会更大,Generator一般采用一个参数量较少的MLM。
4、引入知识的预训练
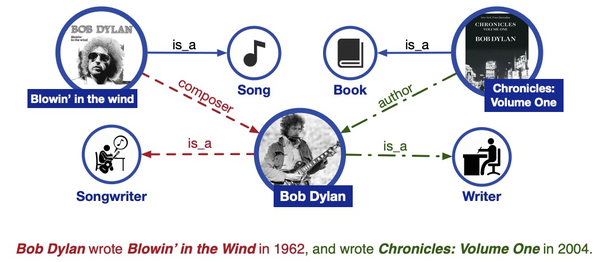
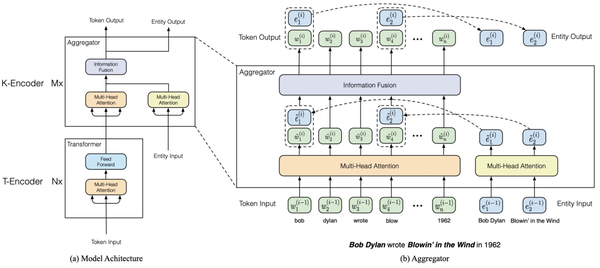
ERNIE: Enhanced Language Representation with Informative Entities(2019)从知识增强的角度对Bert进行优化。相比原来的Bert,ERNIE引入了如知识图谱等外部知识信息。这样的好处在于,有一些文本如果不知道某些词组代表一个实体的话,模型是很难学习的,例如一些人名、地名等。如下面的例子,不知道橘子中的这些实体是书名、歌名,就无法识别出作者的职业。
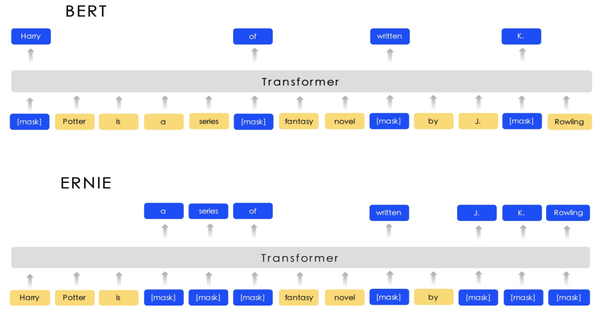
此外,还有一个同名工作ERNIE: Enhanced Representation through Knowledge Integration(2019)也使用了类似的思路,希望通过引入外部知识信息提升预训练模型效果。和Bert主要差别在于,本文将MLM任务分成basic-level、phrase-level、entity-level三种类型,在entity-level mask中,mask掉的不是单个token,而是输入文本中某个entity对应的连续多个token,其和Bert的差异如下图。
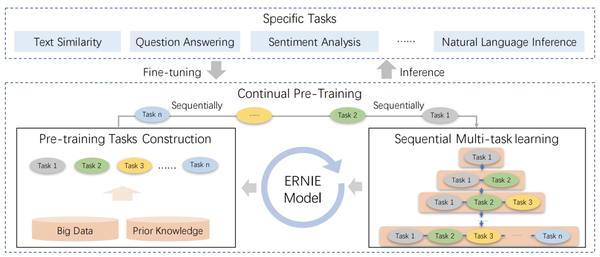
后面这篇工作后续又推出了2.0版本,ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding(2019)。该工作在pretrain阶段引入了很多task来辅助pretrain阶段的学习。首先构造pretrain阶段的任务,主要是无监督或弱监督的训练数据容易获得的任务,同时也会引入知识图谱中的信息构造一些训练任务。接下来,本文采用continual multitask learning的方式,不断构造新的任务,并且以增量的方式进行多任务学习,每来一个任务都把历史所有任务放到一起进行多任务学习,避免忘记历史学到的知识。本文的核心点在于提出的多种构造预训练任务的方式,包括Knowledge Masking Task(即上一篇ERNIE中的对entity或phrase进行mask)、Capitalization Prediction Task、Token-Document Relation Prediction Task等,感兴趣的同学可以阅读论文深入了解。
5、预训练方式的创新
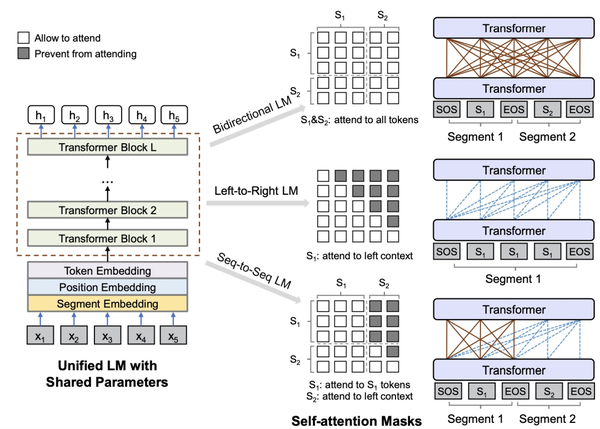
在GPT和BERT的启发下,后续涌现了很多其他类型的预训练语言模型,这里主要介绍UniLM、XLNet、BART这3种。 Unified Language Model Pre-training for Natural Language Understanding and Generation(NIPS 2019)提出了UniLM预训练语言模型。本文首先总结了之前语言模型的特点:EMLo采用前向+后向LSTM、GPT采用从左至右的单向Transformer、BERT采用双向Attention。虽然BERT的双向Attention取得很好效果,但是这种特性也导致其无法像GPT等使用单向方法的语言模型一样适用于文本生成这种任务。UniLM融合了3种语言模型优化目标,通过精巧的控制mask方式来在一个模型中同时实现了3种语言模型优化任务,在pretrain过程交替使用3种优化目标。下图比较形象的描述了UniLM是如何利用mask机制来控制3种不同的优化任务,核心思路是利用mask控制生成每个token时考虑哪些上下文的信息。
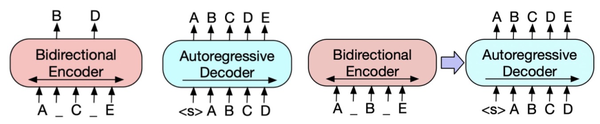
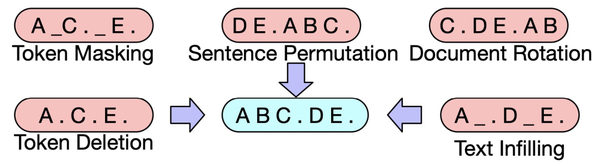
XLNet: Generalized Autoregressive Pretraining for Language Understanding(NIPS 2019)提出了XLNet模型,融合了BERT和GPT这两类预训练语言模型的优点,并且解决了BERT中pretrain和finetune阶段存在不一致的问题(pretrain阶段添加mask标记,finetune过程并没有mask标记)。本文将无监督语言模型分成两类,一类是AR自回归模型,如GPT、ELMo这种使用单向语言模型建模概率分布的方法;另一类是AE自编码模型,如BERT这种通过预测句子中token的方法。XLNet融合了AR模型和AE模型各自的优点,既能建模概率密度,适用于文本生成类任务,又能充分使用双向上下文信息。XLNet实现AR和AE融合的主要思路为,对输入文本进行排列组合,然后对于每个排列组合使用AR的方式训练,不同排列组合使每个token都能和其他token进行信息交互,同时每次训练又都是AR的。但是,实现这种模式也存在很多问题,文中针对这些问题提出了解法,由于篇幅原因具体内容我们会在后续相关文章再进行详细介绍。 BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension(2019)提出了一种新的预训练范式,包括两个阶段:首先原文本使用某种noise function进行破坏,然后使用sequence-to-sequence模型还原原始的输入文本。下图中左侧为Bert的训练方式,中间为GPT的训练方式,右侧为BART的训练方式。首先,将原始输入文本使用某些noise function,得到被破坏的文本。这个文本会输入到类似Bert的Encoder中。在得到被破坏文本的编码后,使用一个类似GPT的结构,采用自回归的方式还原出被破坏之前的文本。



 发表于 2022-9-21 18:02:00
发表于 2022-9-21 18:02:00